
XBRL – the good parts
There’s a lot to like about XBRL.
After centuries of paper, and decades of opaque and proprietary digital formats, XBRL was the breakthrough technology that allowed business reports to be exchanged quickly, widely and reliably.
XBRL is a mature standard that has proven itself in the real world. All listed companies in the US and all major banks and insurance companies in Europe file to their regulators in XBRL. In the UK alone, 4 million companies have submitted over 20 million XBRL filings.
XBRL was designed from the outset to be a global standard, with a modular, extensible structure that allows multiple jurisdictions to augment a common set of base definitions with new labels and country-specific reporting concepts. It has been adopted by dozens of countries on every continent except Antarctica.
XBRL has a rich type system, covering not just numeric data but text, dates, URIs and even user-defined formats – everything needed to capture the machine-readable information in a business report. XBRL also provides a clear means of capturing units of measure, which are often left implicit in other representations.
XBRL includes a standard mechanism for expressing complex dimensional validation rules, and rich rendering features that ensure sender and receiver can share a common view of a business report, while retaining the ability to slice it and dice it for analysis.
XBRL’s specifications are backed up by extensive conformance suites, and a certification process from XBRL International that deliver high levels of interoperability across a wide range of off-the-shelf software.
Though XBRL’s business benefits are clear, technologists delving into XBRL’s syntax and specifications can be forgiven for recoiling in horror.
Good intentions and blunders
All non-trivial standards can be daunting when you approach them at syntax level, with just the specifications to guide you rather than APIs and graphical interfaces. With XBRL, this is especially true.
XBRL was defined back in 2003, in terms of three key technologies that seemed reasonable at the time: XML, XML Schema, and XLink.
XML was a worthwhile refinement of SGML, and it’s a natural choice for semi-structured, “mixed-content” documents like HTML and Inline XBRL. In 2003 XML was still a popular choice for structured data, but JSON provides a much simpler means of transmitting object models from one computer to another, and this is now universally recognised. The world has moved on.
XML Schema is an extremely powerful language for constraining the shape of XML, and still the most widely used technology for this purpose, but it comes with a lot of complexity, not all of which is needed for XBRL.
XLink, meanwhile, has not seen widespread adoption outside of XBRL. It went one way, and the semantic web went another.
To make matters worse, all of the rich functionality that XBRL subsequently gained — for taxonomy-defined dimensions, validation rules, and rendering — was defined in terms of the original syntax, rather than a logical model decoupled from it.
None of this has stopped XBRL from becoming the leading standard for business reporting, but it has made life difficult for developers, and slowed adoption. Indeed, some tech-savvy organisations have found the syntax details sufficiently off-putting that they’ve stuck with proprietary formats, or devised new ones, forgoing the benefits of the XBRL standard.
The Open Information Model
For the last few years, a group of us have been working to improve XBRL’s technical foundations, setting the stage for easier and more widespread adoption of the standard.
The Open Information Model formally defines the syntax-independent logical model that has always been there behind the scenes. It pins down which parts of XBRL’s original XML syntax are semantically significant, and which are irrelevant.
Along the way, we’ve taken the opportunity to simplify the standard by cutting out features that add a lot of complexity without countervailing benefits. Notably, OIM forbids the use of arbitrarily-nested hierarchical structures, which don’t sit comfortably with XBRL’s dimensional model.
We have also defined two new representations of the model, which each provide different benefits over the original XML syntax.
xBRL-JSON
JSON can be trivially serialised and deserialised in every major programming language, making it the format of choice for web APIs.
xBRL-JSON is designed for this environment, as the simplest, clearest expression of the Open Information Model.
It provides a flat, denormalised representation for each data point, with all dimensional information immediately accessible.
Whereas the XML syntax has a range of structures for representing similar information, xBRL-JSON represents all dimensions consistently, whether they are built in to the standard or defined by users in a taxonomy.
The benefits of the new JSON representation become obvious when you see an example.
Here’s an xBRL-XML representation of a single data point:
<dei:EntityCommonStockSharesOutstanding contextRef='context_2' decimals='INF' id='Fact-B90BB051582C5EE9E2AD8C6C79A5CE80' unitRef='unit'> 348952225 </dei:EntityCommonStockSharesOutstanding> <xbrli:unit id='unit'> <xbrli:measure>xbrli:shares</xbrli:measure> </xbrli:unit> <xbrli:context id='context_2' > <xbrli:entity> <xbrli:identifier scheme='http://www.sec.gov/CIK'> 0001652044 </xbrli:identifier> <xbrli:segment> <xbrldi:explicitMember dimension='usgaap:StatementClassOfStockAxis'> goog:CapitalClassCMember </xbrldi:explicitMember> </xbrli:segment> </xbrli:entity> <xbrli:period> <xbrli:instant>2018-04-18</xbrli:instant> </xbrli:period> </xbrli:context>Here’s the xBRL-JSON representation of that same data point:
"Fact-B90BB051582C5EE9E2AD8C6C79A5CE80": { "dimensions": { "concept": "dei:EntityCommonStockSharesOutstanding", "entity": "cik:0001652044", "period": "2018-04-19T00:00:00", "unit": "xbrli:shares", "us-gaap:StatementClassOfStockAxis": "goog:CapitalClassCMember" }, "value": "348952225" }xBRL-CSV
For large data sets, and even some smaller data science applications, it is the venerable CSV file that is the format of choice. CSV on its own leaves out a lot of important metadata, which XBRL brings to the table.
Regulators are increasingly interested in collecting detailed, “transaction level” data, and CSV is ideally suited to this. Our initial tests have shown significant reductions in file size compared to the xBRL-JSON and xBRL-XML representations.
OIM’s CSV representation uses a supporting JSON file to tie the rich XBRL taxonomy model to the rows and columns in a collection of CSV files. By placing facts with the same dimensional breakdown in the same CSV file we avoid a lot of repeated declarations, and put facts with the same dimensional context conveniently together on the same row:
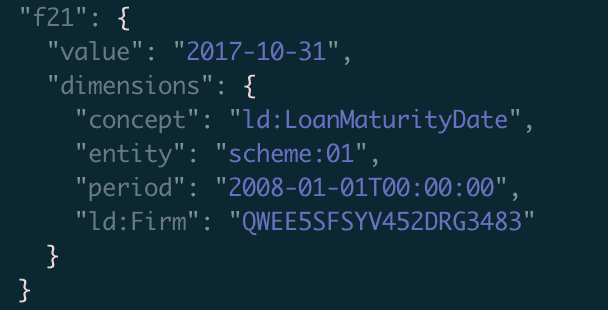
firm,size,country inc,limit,pct collateralized,interest,start,maturity F50EOCWSQFAUVO9Q8Z97,ld:Small,UK,10000000,.70,.040,2001-06-01,2020-12-31 AX378AEV345CAME93E45,ld:Medium,US,20000000,.50,.020,2010-03-01,2019-12-31 QWEE5SFSYV452DRG3483,ld:Micro,PL,30000000,.30,.030,2016-09-01,2017-10-31Here’s the corresponding JSON representation for the first row:
{ "t1.r1.c2": { "value": "ld:Small", "dimensions": { "concept": "ld:CompanySize", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } }, "t1.r1.c3": { "value": "UK", "dimensions": { "concept": "ld:CountryOfIncorporation", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } }, "t1.r1.c4": { "value": "10000000", "decimals": 2, "dimensions": { "concept": "ld:LimitGranted", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "unit": "iso4217:USD", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } }, "t1.r1.c5": { "value": ".70", "decimals": 3, "dimensions": { "concept": "ld:PercentageCollateralisedAtInception", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } }, "t1.r1.c6": { "value": ".040", "decimals": 4, "dimensions": { "concept": "ld:InterestRateChargedAtInception", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } }, "t1.r1.c7": { "value": "2001-06-01", "dimensions": { "concept": "ld:LoanStartDate", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } }, "t1.r1.c8": { "value": "2020-12-31", "dimensions": { "concept": "ld:LoanMaturityDate", "entity": "scheme:01", "period": "2017-05-01T00:00:00", "ld:Firm": "F50EOCWSQFAUVO9Q8Z97" } } }The compactness of the CSV representation is achieved by:
- sharing information across facts in a row
- e.g.
ld:Firm=F50EOCWSQFAUVO9Q8Z97for row 1
- e.g.
- sharing information across facts in a column
- e.g.
concept=ld:LimitGranted; decimals=2; unit=iso4217:USDfor column 4
- e.g.
- sharing information common to the entire file
- e.g.
period=2017-05-01T00:00:00; entity=scheme:01
- e.g.
The CSV format is still under development, but the metadata JSON file is expected to follow the layout of the W3C’s Tabular Metadata specification. It will look broadly like this:
{ "@context": "http://www.w3.org/ns/csvw", ... "oim:documentInfo": { "commonProperties": { "entity": "scheme:01", "period": "2017-05-01T00:00:00", } }, "tables": [ { "url": "loan-data-facts.csv", "tableSchema": { "columns": [ { "oim:columnType": "property", "oim:columnProperty": "ld:Firm" }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:CompanySize" } }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:CountryOfIncorporation" } }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:LimitGranted" } }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:PercentageCollateralisedAtInception", "decimals": 3 } }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:InterestRateChargedAtInception", "decimals": 4 } }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:LoanStartDate" } }, { "oim:columnType": "fact", "oim:properties": { "concept": "ld:LoanMaturityDate" } } ] } } ] }The path to Recommendation status
Standardisation efforts usually take longer than you’d expect, and OIM has been no exception, but it’s now on the home stretch.
We expect the core model and JSON representation to reach the final “Recommendation” status by the middle of 2019, with the CSV representation following by the end of 2019.
For the latest information about OIM, check out specifications.xbrl.org, and look for future posts here on the CoreFiling blog.